Ви не увійшли.
- Теми: Активні | Без відповіді
Сторінки 1
#1 2018-03-14 15:35:33
- Olej
- Учасник

- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
русские символы в Arduino IDE
Вообще то, Arduino IDE (пишут) использует по умолчанию UTF-8 кодировку UNICODE.
Для англоязычных символов (как пишут во всех примерах кода) это не имеет никакого значения.
Но для русскоязычных символов это порождает проблемы, с которыми хотелось бы разобраться.
Когда вообще возникают (могут) русскоязычные символы в Arduino?
1. При выводе на индикаторы ... LCD 1602, например, или TFT (об этих проблемах галдёж на форумах Arduino стоит года с 2011-го ![]() )
)
2. Обмен по вводу-выводу через Serial
3. Обмен с ОС, самописными программами, или Processing на хост-компьютере (и здесь в Linux и Windows будут принципиально разные вещи ... но в чём? насколько? и какими неприятностями выражаться?)
4. При самых разных сетевых обменах
Если кто-то сталкивался с проявлениями этих проблем - поделитесь.
А я поделюсь то, что от себя знаю.
Неактивний
#2 2018-03-14 15:41:14
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
А я поделюсь то, что от себя знаю.
Я скопирую сюда то, что писал на совсем другом форуме:
DarkGenius пише:Первый байт означает какая кодировки и какая версия, второй собственно код символа, если ты пишешь тут двухбайтный код символа в десятичной системе, это о многом говорит. Всё есть в сети, а если тебе лень разбиратся не засоряй форум.
Кириллица в Юникоде
Windows-1251Всё не совсем так просто... И для корректной работы с символьными строками с этим нужно разобраться:
UNICODE - это чисто теоретическая таблица, присвоение кодов символов самым замысловатым языкам ... например, музыкальным нотам. Код UNICODE - всегда 4 байта. Но нигде, ни в одном языке и ОС в таком виде не используется ... не для того предназначается.
UTF-32 - способ кодирования UNICODE значений, каждый символ кодируется как uint32_t.
UTF-16 - способ кодирования UNICODE значений, каждый символ кодируется uint16_t. Это то, как UNICODE понимается в Windows - сдостаточно старый способ представления UNICODE.
UTF-8 - способ кодирования UNICODE значений последовательностью байт переменной длины (это очень важно!) - каждый символ (код UNICODE) представляется как последовательность байт длиной от 1 до 6 (первоначально) байт ... позже, в угоду совместимости с Windows в стандарте было решено не использовать 5 и 6 байтные последовательности (но многим POSIX-ОС это не указ) - это новая кодировка UNICODE, первоначально придуманая авторами UNIX для операционной системы Plan 9 (~2004г.).
В языка C/C++ для представления локализованных символов введен (стандарт C89, позже C99) тип данных wchar_t - широкие символы. И вот тут начинается неразбериха ... в разных ОС wchar_t имеют разные представления: в Windows - uint16_t, в Linux и других новых ОС - uint32_t ("чистый" UNICODE). Никакого отношения wchar_t к UTF-8 не имеют!
Кодировки, кодовые страницы: CP-866, CP-1251, KOI-8r, ... и ещё 1001 шт. - это прошлый, ... или даже позапрошлый день... когда все иноязычные символы представлялись 1-м байтом.
Все способы кодирования UNICODE - UTF-8, UTF-16, UTF-32 - к кодовым страницам никакого отношения не имеют, они в единой кодировке представляют все возможные в природе символы.
Все новые языки программирования: Python, Go, Swift, Kotlin, Tust ... - используют кодировку UTF-8 по умолчанию.
Но для аппаратного обмена (индикаторы, дисплеи, светодиодные панели, ...) нужно преобразовывать любое представление в 1-байтовое. И вот это (как это делать) заслуживает детального обсуждения.
С какой целью копирую?
Возможно, кого-то заинтересует до конца разобраться с этими проблемами ... или поэкспериментировать для уточнения.
Неактивний
#3 2018-03-14 15:49:39
- Green
- Учасник

- Зареєстрований: 2015-11-08
- Повідомлень: 593
Re: русские символы в Arduino IDE
Если кто-то сталкивался с проявлениями этих проблем - поделитесь.
А я поделюсь то, что от себя знаю.
Нужно было выводить кириллицу в кассовый аппарат. Дабы было всё красиво, написал перекодировщик UTF-8 в CP-866. Проблем не было.)
Неактивний
#4 2018-03-14 15:55:52
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
Olej пише:Если кто-то сталкивался с проявлениями этих проблем - поделитесь.
А я поделюсь то, что от себя знаю.Нужно было выводить кириллицу в кассовый аппарат. Дабы было всё красиво, написал перекодировщик UTF-8 в CP-866. Проблем не было.)
Вот об этой глупости ... фиче, простите, я и говорю: когда каждый сам для себя пишет перекодировщик... : на каждый чих и на каждую кодовую таблицу - пишем свой перекодировщик.
Только при смене операционной системы (Windows на Linux, или наоборот) или модели оконечного устройства (другой "кассовый аппарат") - всё это посыпется!
Остання редакція Olej (2018-03-14 15:56:46)
Неактивний
#6 2018-03-14 17:02:14
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
Ардуино IDE и КА у заказчика. Какие варианты? Что то поменяется - буду только рад.)
Не ... ну, если "бабло молотим" - так только на пользу ... и флаг в руки: "сто старушек - сто рублей!"
Но вот если для себя делать, и что-то посложнее чем простейший управляющий контроллер (это тоже имеет право быть, но сейчас о другом ... например об обмене с хост-компьютером через Serial) - то всё становится совершенно не так весело.
Остання редакція Olej (2018-03-14 17:02:55)
Неактивний
#7 2018-03-14 18:35:05
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
UNICODE - это чисто теоретическая таблица, присвоение кодов символов самым замысловатым языкам ... например, музыкальным нотам. Код UNICODE - всегда 4 байта. Но нигде, ни в одном языке и ОС в таком виде не используется ... не для того предназначается.
UTF-32 - способ кодирования UNICODE значений, каждый символ кодируется как uint32_t.
UTF-16 - способ кодирования UNICODE значений, каждый символ кодируется uint16_t. Это то, как UNICODE понимается в Windows - сдостаточно старый способ представления UNICODE.
UTF-8 - способ кодирования UNICODE значений последовательностью байт переменной длины (это очень важно!) - каждый символ (код UNICODE) представляется как последовательность байт длиной от 1 до 6 (первоначально) байт ... позже, в угоду совместимости с Windows в стандарте было решено не использовать 5 и 6 байтные последовательности (но многим POSIX-ОС это не указ) - это новая кодировка UNICODE, первоначально придуманая авторами UNIX для операционной системы Plan 9 (~2004г.).
Здесь есть ещё один аспект, который я сразу забыл отметить - связанный с порядком байт в компьютере: BE или LE (big-endian или little-endian) - какой байт в 16 или 32 бит int считается младшим (в порядке адресации байт). Это очень важно при обменах: обменах между процессорами разных архитектур, сетевых обменах TCP/IP и т.д.
BE: IBM 360/370/390, Motorola 68000, SPARC ... + все сетевые обмены всех протоколов TCP/IP
LE: Intel x86, USB, конфигурация PCI, таблица разделов GUID (для идентификации дисков и др. целей)
Кстати ... я не знаю BE/LE относительно процессоров AVR, на которых собраны Arduino?
Поэтому и кодировки UTF-16 тут же развалились на 2 новых: UTF-16LE (это Windows wchar_t, как я понимаю) и UTF-16BE.
А относительно UTF-8 ещё можно дополнить:
- для UTF-8 нет проблемы порядка байт ... в том числе и при сетевых обменах;
- UTF-8 - самосинхронизирующийся код: при обрыве потока текста в любом месте, после его восстановления легко восстанавливается начало очередного символа (по формату 1-го байта).
Неактивний
#8 2018-03-20 23:24:56
- andriano
- Гість
Re: русские символы в Arduino IDE
Для AVR - LE.
#10 2018-03-21 21:11:21
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
2. Обмен по вводу-выводу через Serial
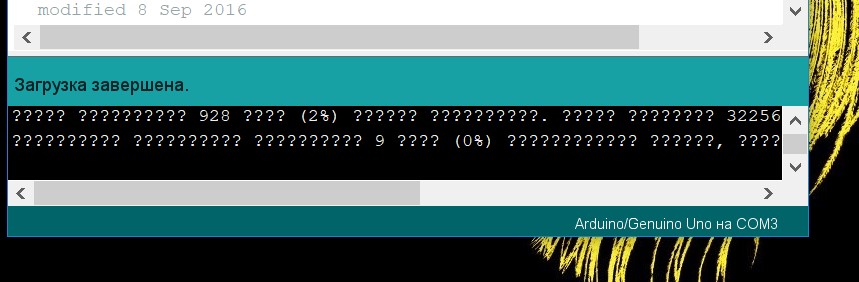
Обмен через Serial (USB) в Arduino кода UTF-8 корректно шёл всегда.
А вот отображение кодов UTF-8 в мониторе порта Ardoino IDE до самого последнего времени глючило ... что-то, наверное, связанное с задержками поступления байт.
Выглядит это так:
Эти искажённые символы проявляются как в версии 1.6.1 и 1.8.1
Это глюк именно Arduino IDE.
(3 строки там потому, что считанную с Serial строку скетч ретранслирует обратно в Serial 3-мя разными способами)
Остання редакція Olej (2018-03-21 21:13:06)
Неактивний
#12 2018-03-21 21:18:52
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
А кроме того, в качестве монитора сериального порта можно использовать ещё одни штатный монитор сериального порта (утилиту), во всех существующих операционных системах, допускающий настройку отображения во всех мыслимых в природе кодировках - это Putty, столь глубоко любимая в Windows.
Неактивний
#13 2018-03-21 21:21:28
- Olej
- Учасник
- З Харьков
- Зареєстрований: 2018-03-08
- Повідомлень: 234
Re: русские символы в Arduino IDE
В Linux, как всегда, всё гораздо проще и разнообразней по возможностям...
В конечном счёте, мы просто можем пользоваться консольными утилитами Linux без любых промежуточных приложений.
По крайней мере, это очень полезно для тестирования при непонятных нарушениях работоспособности!
И убеждаемся, что UTF-8 передаётся в оба конца без искажений.
Неактивний


Сторінки 1