Ви не увійшли.
- Теми: Активні | Без відповіді
#1 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 21:35:38
Всегда казалось, что сдвиг это команда LSL (LSR) с установкой флага переноса
Це вже деталі імплементації для конкретної архітектури. Я маю на увазі з точки зору стандарту мови програмування в загальному. Він нічого "не знає" про біти, флаги та інструкції.
#2 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 21:10:38
За стандарт не скажу, честно не знаю. Но помню книжка писала, что если не указано явно unsigned, то по умолчанию переменная всегда signed.
Саме так. А при зсуві signed:
The result of E1 << E2 is E1 left-shifted E2 bit positions; ... If E1 has a signed type and nonnegative value, and E1 × 2^E2 is representable in the result type, then that is the resulting value; otherwise, the behavior is undefined.
#3 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 21:04:50
Та блин, эти стандарты уже так разрослись и отличаются, что уже не уследишь. ))
Стандартів для мов програмування не так уже й багато. Але так, вендори заліза клепають свої фреймворки з велосипедами на костилях. Тут нічого не поробиш, се ля ві.
#4 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 20:51:52
та дурня. UL это просто unsigned long, т.е. захватывает 4 байта. Если я напишу 1ULL это будет восемь байт, то шо, я еще круче?
Суть не в long, а в unsigned. Поведінка (1 << 15) при 16-бітному int не визначена стандартом. Те ж саме з (1 << 31) на платформах з 32-бітним int.
#5 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 20:46:05
Не в либах дело. Например, для размещения данных во флеш, у gcc используется PROGMEM
В gcc є підтримка named address spaces (ISO/IEC DTR 18037), так що в C __flash працює (для читання генерується lpm). В arduino, яке базується на C++, такого не буде.
Это же касается и асм вставок, надо писать именно так, как хочет конкретный компилятор, и пофиг что у другого по другому, они никогда не будут совместимы в этом плане.
Бо inline assembler не є частиною стандарту, це розширення конкретного компілятора.
#6 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 20:30:46
Посмотрел. Раскладывается в тот же #define bit(b) (1UL << (b)).
1UL. В avr-libc просто 1.
#8 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 19:37:55
важливіше розуміти як воно працює, а не щоб було красиво.
Одне іншому не заважає, а навіть допомагає. "Красиво" - це не мета, а наслідок коректності, зрозумілості та ефективності коду.
Це с"огодні в мене такі налаштування таймеру такі, а якщо завтра захочу встановити інші?
Так усе у одному місці і з пам"яткою "що за що відповіда"....
Так в чому проблема залишити все там само і так само, тільки записувати значення в регістр один раз замість чотирьох?
Вище наведено приклади, як можна написати щоб було і зручно, і правильно.
Мене більше турбує обробка преривання, до ц"ого часу я обходився оператором if, і на комбінацію switch case прейшов щоб не пхати у код goto .
Так всі гілки однакові, відрізняються лише значення змінних. Навіщо їх дублювати?
Нумеруйте все з нуля, окрема змінна Shag стає непотрібною. Всі ваші if та case перетворюються на:
static const uint8_t pins[4] = { 2, 4, 7, 8 };
static volatile uint16_t ocr[4][2];
ISR ...
{
uint8_t idx = Serv;
Serv = (idx + 1) % 8;
uint8_t channel = idx / 2;
uint8_t state = idx % 2;
digitalWrite(pins[channel], !state);
OCR1A = ocr[channel][state];
}Тільки не забувайте, що змінні, які читаються в обробнику переривань та більші за 8 біт, з основної програми потрібно оновлювати з вимкеними перериваннями. Ви ж тільки шматок коду показали, тому я не знаю, який там у вас тип у Serv_1_1 та інших.
#9 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 14:43:30
Правильно мабуть
TCCR1B |= (1 << CS10); TCCR1B &= ~(1 << CS11); TCCR1B |= (1 << CS12);
Не зовсім. Правильно, щоб значення в регістрі оновлювалось однією інструкцією. А для працюючого таймера правильніше спочатку зупинити його, сконфігурувати, потім запустити. Звісно, якщо потрібно залишити якісь біти незмінними, то прочитати поточне значення і застосувати маску.
Якщо ж виставляється чи скидається лише один біт в одному з нижніх 64 регістрів, то компілятор може заоптимізувати це в одну інструкцію sbi чи cbi.
Або макросів навернути
Або static inline функцію. Але це вже синтаксичний цукор.
#10 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 13:47:28
Якщо розписати так ... то таки чесно виконує безсмислену операцію
Справа не в беззмістовній операції, а в тому, що якби було би, наприклад,
TCCR1B |= (1 << CS10);
TCCR1B |= (0 << CS11);
TCCR1B |= (1 << CS12);то по закінчені цього коду таймер би уже натікав більше ніж треба.
Для покращення читабельності можна ще, наприклад, так:
uint8_t tmp = (1 << WGM12);
tmp |= (1 << CS10);
tmp |= (0 << CS11);
tmp |= (1 << CS12);
TCCR1B |= tmp;#11 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » Вчора 12:35:10
Мені здається що ця конструкція не має смислу. Можливо компілятор її навіть виріже.
Не виріже, бо регістри volatile.
Насправді, в більшості випадків така побітова конфігурація на практиці не має негативного ефекту. Лише, наприклад, при виставленні дільника на 1024 можна з подивом виявити, що Output Compare спрацьовує раніше ніж очікується. Але все одно краще писати зрозуміло і правильно.
А для насправді точних таймінгів потрібно ще й Timer Prescaler скидати, який спільно з Timer0 використовується ![]()
#12 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-21 22:23:27
TCCR1B |= (1 << WGM12); // включить CTC режим TCCR1B |= (0 << CS10); // Установить биты на коэффициент деления TCCR1B |= (1 << CS11); TCCR1B |= (0 << CS12);
Дільник таймера завжди виставляйте однією операцією запису:
TCCR1B = (1 << WGM12) | (0 << CS10) | (1 << CS11) | (0 << CS12);Або, якщо значення інших бітів невизначені:
TCCR1B = (TCCR1B & ~((1 << CS10) | (1 << CS11) | (1 << CS12)))
| (0 << CS10) | (1 << CS11) | (0 << CS12);Або, якщо за логікою заздалегідь відомо, що таймер зупинено (в CS1[2..0] нулі):
TCCR1B |= (0 << CS10) | (1 << CS11) | (0 << CS12);#13 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-21 20:35:08
if (Serv==1) { // Проверка для какого канала управления производится формирование if (Serv==2) { // Все тоже самое для канала 2, меняется только номер вывода на котором ...
Не лінь оце вам стільки коду дублювати? ![]() Я би зробив цикл і таблички.
Я би зробив цикл і таблички.
прошу покритикувати, особливо в частині швидкості виконаня.
Це як раз той випадок, коли має сенс замість digitalWrite() писати напряму в регістри GPIO.
#14 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-21 20:25:51
До речі, а що взагалі не так з тою лібою servo з професійної точки зору?
Та як і в багатьох бібліотеках, деякі параметри прибиті цвяхами - без модифікації коду самої бібліотеки їх не зміниш.
Там і так уже AVR-специфічний код, чому б не транслювати ардуінівські піни на регістри AVR при ініціалізації, а в обробнику лише писати в них.
При зміні значення одного каналу фаза наступних зміщується. Якщо сумарне значення тривалостей для всіх каналів перевищує 20 мс, період слідування імпульсів збільшується. Зрозуміло, що така специфіка імплементації, але її треба мати на увазі.
Дещо дивують конструкції типу
if(SERVO(timer,Channel[timer]).Pin.isActive == true)Макроси, що посилаються на члени класу, і т.п.
#15 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-20 17:01:51
Ну я так розумію там відтворюється якийсь проект від Алекса Гувера. Краще тоді з мінімальними змінами. У нього, судячи з каментів в коді, теж на 8 мгц щось не так.
Та там не зрозуміло, які коментарі від Гувера, а які вже від автора топіка. Якщо оригінальний код - це ось цей, то там ніякого Servo взагалі нема.
(А тут тема перейшла на нову сторінку, то того повідомлення з кодом вже не видно навіть в режимі редагування)
#16 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-20 16:14:12
"56 кроків", 40% і т.д. влаштовує не дуже
Ну у вас декілька варіантів:
1. Розібратись, чому не працює зі "стандартною" Servo. Мені не вдалося відтворити ту поведінку, що ви описуєте: імпульси йдуть чітко з періодом 20 мс і очікуваною тривалістю. Значить, або ми запускаємо різний код (чи скомпільований з різними налаштуваннями), або не враховуєм якісь умови відтворення, або ви невірно описали поведінку.
Яка інформація потрібна для подальшого аналізу - вказано в попередніх повідомленнях.
2. Реалізовувати поетапно те ж саме, що робить Servo (апдейт OCR в обробнику переривання), і дивитись, на якому етапі перестає працювати. Тоді стане зрозуміло, і чому перестає, і чи можна це побороти.
3. Оптимізувати ваш варіант із відліком інтервалів по перериванню, а не по значенню TCNT. При грамотній реалізації обробник можна вмістити в декілька десятків тактів, на 8 мегагерцах де дасть роздільну здатність у порядка 200-300 кроків. Але у вас же там ще nRF24 планується, чи не так? Будуть ще переривання і затримки від SPI. Як воно із вашим кодом взаємно впливатиме - передбачити складно. Можливо, доведеться також оптимізувати і SPI.
4. Обрати іншу апаратну платформу, яка краще підходить для цієї задачі. Он пишуть, у ESP32 аж 16 апаратних jitter-free каналів PWM. Можливо, варто розглянути інший драйвер BLDC, який керується іншим способом. Якось не дуже раціонально перетворювати цифрове значення у сервоподібну PWM, яка потім драйвером перетворюється на іншу PWM вже для двигунів.
Зазвичай спочатку формулюється задача, аналізуються необхідні ресурси, вже потім обирається залізо для реалізації. А ви штучно створили собі обмеження і намагаєтесь їх героїчно подолати.
#18 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-19 17:12:13
№18 По кварц не скажу, занадто дрібний
Там же Atmega328P в TQFP корпусі? Подивіться оцилом на XTAL2 (8-й пін).
але при переносі коду на плату 16 МГц частота подвоюється, відповідно встановлено 8 МГц...
При переносі скомпільованого коду чи при компіляції коду під 16 МГц плату?
Всі таймінги в одиницях часу (мілі- та мікросекунди) спираються на значення макроса F_CPU, що передається під час компіляції. Яке значення передається у вас?
Так що з вашим кодом, що з стандартною біліотекою Servo є проблеми з синхронізацією
Втретє кажу: виставте часовий масштаб, щоб було видно багато імпульсів. 100 мс на поділку, наприклад. І покажіть разом із сигналом від сервотестера.
#19 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 23:22:11
замість digitalwrite пишіть в регістр напряму. Можна на асемблері
Там можна після завершення останнього імпульса заряджати таймер одразу на початок наступного цикла. Бо майже 90% викликів ISR іде вхолосту. Зручніше це, мабуть, буде в режимі FastPWM замість CTC.
Або використати один компаратор для 20 мс циклу, а другий для відмірювання інтервалів дригання пінами.
І якщо піни обрати з однієї банки, то й виставляти їх одночасно однією інструкцією.
Непахане поле для оптимізації.
#20 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 21:14:14
При спробі завантажити код виходить якась ху.....
А, побачив пости з кодом при редагуванні повідомлення. Не відображається, бо там в коментарях посилання на ютуб.
#21 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 21:06:34
Те що генерує ваша
Ваш код
Код, що я запостив, на початку setup() понижує тактову частоту вдвічі, щоб на 16-мегагерцовій платі працювало як на 8-мегагерцовій. Тому коли запускаєте на 8-мегагерцовій, інтервали будуть збільшені вдвічі. А по суті це те ж саме що "Стандартна Servo".
Але на фото масштаб 20 мс/, між імпульсами виходить 80 мс, тобто збільшені в 4 рази чомусь.
У вас там часом не 4 МГц резонатор? Чи може не ту частоту обираєте при збірці?
Чим взагалі збираєте? Покажіть, які опції передаються компілятору.
А так, на фото інтервали-то рівні. На відео - таке враження, що осцил просто не може засинхронізуватись. Зменшіть часовий масштаб, щоб з десяток імпульсів було видно.
Стандартна Servo
Знову ж таки, осцил не синхронізується.
Таке враження, що імпульси від ардуіни йдуть з набагато меншою частотою ніж від сервотестера.
Покажіть у меншому масштабі.
Моя, сжера 40% ресурсу
частота виклику 25 кГц...
Тобто гранулярність 40 мкс. Для діапазона 160-2400 мкс виходть 56 кроків. Якщо цього достатньо, то чому б і ні?
#22 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 17:51:12
При спробі завантажити код виходить якась ху.....
Ну завантажте як файл і дайте посилання на нього.
8-МГц плат щось я у себе не знайшов, ось запустив на 8 мегагерцах наступний код на Nano з 16 МГц резонатором:
#include <Arduino.h>
#include <Servo.h>
Servo servo;
void setup()
{
{
uint8_t sreg = SREG;
cli();
CLKPR = _BV(CLKPCE);
CLKPR = 0b0001;
SREG = sreg;
}
pinMode(LED_BUILTIN, OUTPUT);
servo.attach(6, 150, 2400);
servo.write(0);
}
void loop()
{
static bool state = false;
digitalWrite(LED_BUILTIN, (state = !state));
delay(500);
}platformio.ini:
[env:pro8MHzatmega328]
platform = atmelavr
board = pro8MHzatmega328
framework = arduino
lib_deps =
arduino-libraries/Servo@1.3.0Блимання світлодіодом в loop() - це чисто щоб впевнитись, що працює на 8 МГц.
Нічого не смикається, чіткі імпульси кожні 20 мс тривалістю 150 мкс. Тривалість самих імпульсів коливається в межах декількох мікросекунд, що цілком очікувано.
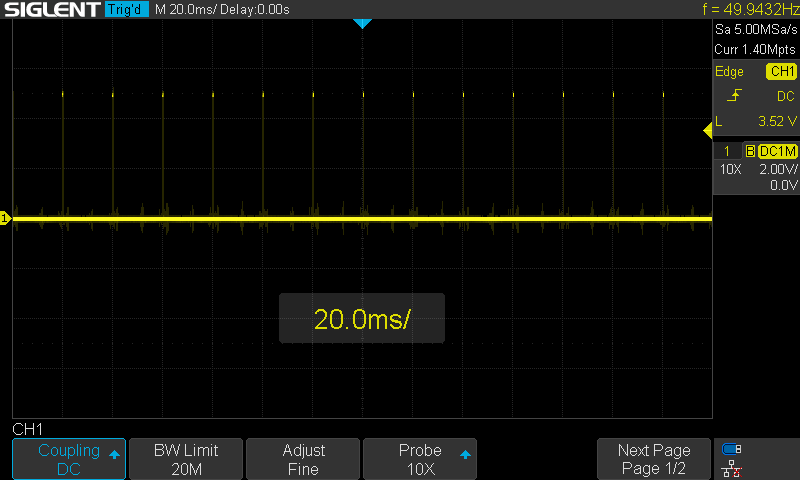
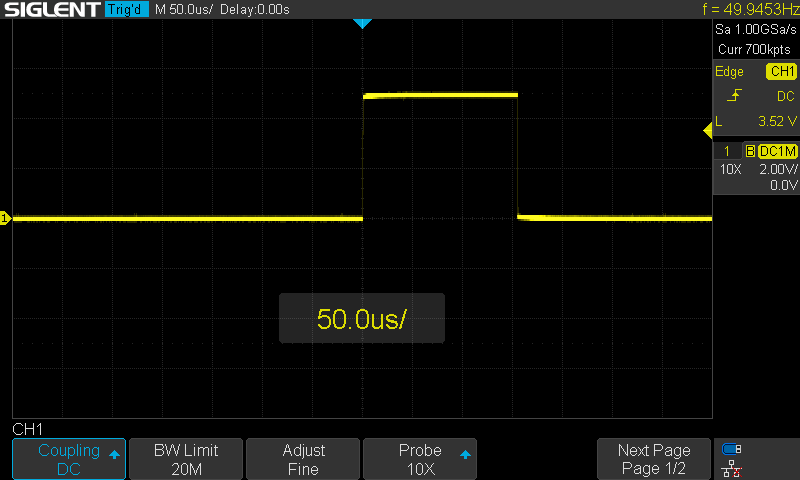
#23 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 15:35:52
№9 - бібліотека Servo.h працює по таймеру, тому що там у основному циклі неважливо, просто буде виконуватися повільніше.
Обробник самої Servo виконується певний час і може блокувати інші переривання, наприклад, від UART, внаслідок чого починаючи з певних бітрейтів губитимуться байти.
Там TCNT1 та OCR1A апдейтяться прямо в обробнику COMPA з поправками на час виконання коду. Такий підхід має певні граничні умови, які, можливо, у вашому випадку не виконуються.
Бібліотека Servo написана дилетантами для дилетантів і не призначена для використання в промислових рішеннях. Втім, як і весь ардуіно фреймворк.
Нечіткість сигналу - той імпульс що по центру генерується стабільно, а от той що зліва "мерегтить" і "плава" ліворучь-праворучь..
Це імпульси при єдиному активному каналі, як розумію? Кажу ж, може осцил чіпляється за останній впійманий, а подальші просто не малює. А насправді плаває інтервал між усіма імпульсами.
Якби ви показали мінімальний відтворюваний приклад, можна було б зібрати його у себе, прошити і подивитись поведінку на осцилографі в реальному часі. Показати код не заради цікавості просять, а щоб відтворити проблему і проаналізувати її.
Необхідну мінімальну триваліть імпульсів так поки не озвучили.
#24 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 04:44:42
№4 - варіант з таймером якраз колупаю, підозрюю що вийде щось типу "лікування зубів через сраку"...
Якщо підходити до задачі серйозно, то для початку потрібно визначитись із граничними параметрами: мінімальна тривалість імпульсів, максимальна тривалість, гранулярність (кількість кроків між мінімумом та максимумом, або ж тривалість одного крока), допустиме відхилення.
А також: чи допустимо генерувати імпульси послідовно, наприклад, при 4 каналах - з інтервалом по 5 мс між каналами, або ж передні фронти на всіх каналах мають бути синхронними. Скільки часу допустимо з точки зору інших компонентів ПЗ проводити в обробнику переривання (у вас же не лише PWM буде, а і якась комунікація з іншою периферією), і т.д.
При не дуже жорстких умовах напрошується очевидне просте рішення: в обробнику періодичного переривання по таймеру виставляти всі канали в одиниці, потім тупо крутити спінлок, скидаючи потрібний канал через заданий проміжок часу.
#25 Re: Програмування Arduino » Arduino Pro 8 МГц і бібліотека Servo » 2026-07-18 02:27:32
у основному циклі лише SerV.attach(6,150,2400); і SerV.write(0);
Як вже сказали, не треба так. Для початку винесіть SerV.attach() і SerV.write() в setup(), а loop() залиште пустим.
150 мікросекунд - не замало для мінімального імпульса? На 8 мегагерцах це лише 1200 тактів.
Скільки вашому BLDC потрібно для мінімального рівня?
Спробуйте поставити min 1000 і max 2000. А у write передайте 90. Подивіться, чи відповідають тривалості імпульсів очікуваним 1500 мкс.
Взяв іншу плату з кварцем на 16 МГц
На Pro та інших міні-платах зазвичай не кварц, а кераміка. Але у вашому випадку це не має суттєво впливати.
залив той самий скетч - на осцилографі чіткий сигнал...
Так в чому саме полягає "нечіткість" сигналу? По одній розмитій фотці з двома імпульсами не дуже зрозуміло. Період слідування імпульсів плаває? На скільки мілісекунд відхиляється від 20 мс? Чи тривалості не відповідають очікуваним?