Ви не увійшли.
- Теми: Активні | Без відповіді
#1 Re: Проекти » Побудова сигналізації обриву шлейфу на базі реле HFD27/005H та Arduino » 2026-06-30 17:34:01
Питання чи можу я використати інше ПЗ для підключення?
Якщо там якийсь стандартний протокол, то можливо, і зможете. Але ж ми не знаєм, що там за протокол.
Якщо якийсь пропрієтарний, і документації нема, то тільки реверс-інженерити і розробляти своє ПЗ з нуля. Зовсім не факт, що це буде швидше чи дешевше, ніж замінити всю систему.
Працювали на ПЗ НПП "Потенціал" Зебра. Тепер відновлюю, але техпідтримки немає (вони були в Рубіжному).
Схоже, дійсно, вам потрібно знайти спеціаліста, який працював саме з тими сигналізаціями. А щоб його знайти, потрібно шукати по номенклатурній назві вашої системи.
Пошук в гуглі показує, що продукція цього підприємства досі продається. Може має сенс звернутись до тих, хто продає.
#2 Re: Проекти » Побудова сигналізації обриву шлейфу на базі реле HFD27/005H та Arduino » 2026-06-29 17:27:21
Так в чому полягає питання? І для чого Arduino?
#3 Re: Апаратні питання » Снабберний RC ланцюжок паралельно симістору » 2026-06-21 19:38:13
Та якби ж воно відтворювалось..
Маю на увазі, за яких умов вимикається після того як самовільно увімкнулось? Теж саме по собі чи поки не знеструмите?
#4 Re: Апаратні питання » Снабберний RC ланцюжок паралельно симістору » 2026-06-21 16:57:36
Потужність же невелика? Якщо там тільки on/off, то реле має буде достатньо.
Або діодний міст + мосфет. Тоді оптопара все одно потрібна, і якщо проблема саме через неї, то треба вживати заходів.
А снаббер в будь-якому разі краще залишити.
#5 Re: Апаратні питання » Снабберний RC ланцюжок паралельно симістору » 2026-06-21 15:52:13
Є в мене кавоварка, в якій іноді самовільно вмикається помпа.
А за яких умов вимикається? Може й через dV/dt, якщо з мережі якась гидота приходить, а на вході нема фільтра. Симісторний снаббер може бути не розрахований на те, що у нас в мережі буває.
Але від одиничного імпульса вмикалося б лише на півперіода, навряд чи взагалі було би помітно.
Може й оптопара починає трохи відкриватись, і цього стає достатньо. Світлодіоду багато не треба. Заземлення ж мабуть немає? Спробуйте перевернути вилку в розетці, іноді допомагає ![]()
#6 Re: Апаратні питання » Снабберний RC ланцюжок паралельно симістору » 2026-06-21 12:44:47
А щодо dv/dt.. воно якось може завадити симістору чи оптрону?
Симістор самовільно відкриватиметься, коли має бути закритим. А так щоб вийшов з ладу - то хіба що тільки велике v, без /dt.
Оптрону навряд чи якось завадить.
Однозначно сказати, чи працюватиме без снаббера стабільно, навряд чи можна, бо залежить від багатьох факторів. З чисто активним постійно підключеним навантаженням може й буде. Також є так звані безснабберні симістори (snubberless triac).
Я би тут розглядав з іншого боку: які аргументи щоб не ставити снаббер. Вартість конденсатора з резистором, місце на платі. І які можливі наслідки, якщо таки працюватиме не як очікується.
#7 Re: Апаратні питання » Снабберний RC ланцюжок паралельно симістору » 2026-06-20 23:04:14
Але якщо у нас симістор з управлінням через оптрон з zero-cross - симістор і вмикається і вимикається при нульовій напрузі на ньому і нульовому струму, і викидів напруги бути не повинно?
Так якщо навантаження індуктивне, нуль напруги не співпадає з нульом струму. (Edit: а, мабуть маєте на увазі, що вмикається при нулі напруги, а вимикається при нулі струму.)
Крім того, стрибки dV/dt можуть відбуватись не лише по причині закривання симістора.
Також, окрім захисту самого симістора, снаббер може суттєво зменшити EMI.
#8 Re: Апаратні питання » Не завантажуються проекти на ардуіно уно » 2026-06-18 11:03:15
Не можу загрузити проект робить лише один і завжди при спробі завантажити без нічого чи інший проект то воно нічого не робить
В чому завантажуєте, в Arduino IDE? Увімкніть "Показувати докладний вивід протягом завантаження" і покажіть, що там пише.
#9 Re: Апаратні питання » Помогите собрать светофор » 2026-06-16 10:08:20
Який сенс у ШІ-помийній відповіді на питання семирічної давнини?
#10 Re: Програмування Arduino » Вимірювання швидкості обертання за допомогою квадратурного енкодера » 2026-06-14 09:28:17
Phase difference between outputs 90°±45° between A and B (1/4 T ± 1/8 T)
Точно. Тоді множити на 8.
#11 Re: Програмування Arduino » Вимірювання швидкості обертання за допомогою квадратурного енкодера » 2026-06-13 17:39:23
rpm треба ділити на 60
Так, звісно ж ділити. Думав про період, помножив частоту ![]() Виправив.
Виправив.
а коефіцієнт 8, бо по даташиту 1/4 оберту з точністю +-1/8
А тут не зрозумів, чому 8? Pulses Per Revolution - кількість імпульсів на оберт на одній фазі, так же? У імпульса два фронта, фази дві, виходить 4 фронта. Чи там прогальність не 50%? На картинці з осцилограмою наче схоже на 50%.
Якщо не 50%, або фази зсунуті не на 90°, тоді, звісно, потрібно робити поправку.
таке потягне лічильник
Цікава штука, для певних застосувань має добре підходити. Але чи варто топікстартеру звʼязуватись із 1-wire для його задачі - то вже йому видніше.
#12 Re: Програмування Arduino » Вимірювання швидкості обертання за допомогою квадратурного енкодера » 2026-06-08 23:09:02
По перше, енкодер хоч і оптичний, але тригерів Шмідта всередині немає.
Тригери Шмітта є на GPIO пінах атмеги. Гістерезис десь 100 мВ при 5 В Vcc.
Для компенсації кривих фронтів є таке рішення
При правильній реалізації ніякої "компенсації кривих фронтів" не потрібно.
Ось приклад для 4-квадрантного енкодера, конечний автомат - LUT з 32 елементів:
class encoder
{
uint8_t state { 0 };
static inline const uint8_t table[] = {
// in: ab aB Ab AB
0b000'01, 0b001'01, 0b010'01, 0b011'01, // 000 ab
0b000'01, 0b001'01, 0b010'01, 0b110'01, // 001 aB
0b000'01, 0b001'01, 0b010'01, 0b111'01, // 010 Ab
0b000'01, 0b001'01, 0b010'01, 0b011'01, // 011 AB
0b000'00, 0b001'01, 0b100'01, 0b110'01, // 100 Ab_b
0b000'10, 0b101'01, 0b010'01, 0b111'01, // 101 aB_a
0b000'01, 0b001'01, 0b100'01, 0b110'01, // 110 AB_b
0b000'01, 0b101'01, 0b010'01, 0b111'01, // 111 AB_a
};
public:
int8_t update(uint8_t in)
{
uint8_t act = table[state | in];
state = act & 0b111'00;
return 1 - (act & 0b000'11);
}
};На вході update() два молодших біта - стани ліній A та B. На виході: -1, 0 або +1.
Лічильник клацає по фронту і спаду кожної фази, тобто в 4 рази швидше - це треба врахувати.
t = 1 / (rpm_max * 60 * ppr * 4)
Edit: t = 1 / (rpm_max / 60 * ppr * 4)
Це дасть мінімальний час між фронтами. А там уже дивіться, чи забезпечить потрібний таймінг та чи інша реалізація.
Всі зовнішні interrupts, доступні для Atmega328, зайняті.
Не до будь-якої ноги можна підключити енкодер.
У атмеги є Pin Change Interrupt на всі GPIO ноги.
У деяких інших контролерів (STM32, CH32) у таймера-лічильника є спеціальний режим для енкодера.
#14 Re: Програмування Arduino » Не видно Arduino Uno r3 в COM портах » 2026-06-04 23:30:37
Колись давно я записав на Arduino Uno r3 keyestudio скетч, щоб цю ардуінку визначало як клавіатуру
Записували ж мабуть у допоміжну atmega16u, яка виконувала функцію USB-UART адаптера. Тепер вона вже не адаптер, а інший пристрій.
Що саме і як ви туди записували?
Прошити скетч у "центральну" атмегу можна декількома способами.
Як уже зазначили, можна підключити ISP-програматор і прошивати.
Якщо у "центральної" атмеги звичайний бутлоадер, що з працює по UART, і є доступ до його пінів RX/TX, то можна підключити до них зовнішній USB-UART адаптер і прошивати.
Гадаю, можна підключитись ISP-програматором і до тієї допоміжної атмеги, і залити туди оригінальну прошивку USB-UART адаптера "як було". А може на ній вже є якийсь свій бутлоадер, який активується сигналами на пінах. Потрібно знати, що там було, і що ви туди залили.
#15 Re: Апаратні питання » Китайський контроллер двигуна DC 12V-60V 70A 4000W DC Durable Motor » 2026-05-21 22:37:00
Всередині контроллера - схема на компараторі; на одному вході пилообразна напруга, на іншому - напруга з потенціометра; просто і безхитрісно.
Цікаво. Ну хоч не на 555 таймері ![]()
І само собою, захотілось прикрутити замість потенціометра ардуїнку
Чи не простіше взагалі відімкнути той генератор пили з компаратором, а мостом керувати з ардуінки напряму?
#16 Re: Різне » Задатчик 4-20ma » 2026-05-16 10:50:20
2 канала - 24 вольта петля(пасив) і 4_20ма до 200мв прямий(актив)
Щось не дуже прояснили. Вам трансміттер для струмової петлі потрібен?
XTR117 (і загалом 4-20mA signal conditioners).
AD693
Можна і на дискретних компонентах: операційник, транзистор, кілька резисторів.
Loop-Powered 4mA to 20mA Transmitter Circuit
Convert 1V to 5V Signal to 4mA to 20mA Output
Introduction to 4-20mA Current Loop Transmitters cтр.14
oled -3 key-щоб бачити що виходить
Передавач окремо, джерело сигналу окремо. Якщо аналоговий потрібен, то з ардуіни його потрібно чимось формувати. Це або зовнішній DAC, або ШІМ. Якщо дискретний, mark/space/idle - можна двома GPIO пінами обійтись (навіть одним, якщо дуже треба).
#17 Re: Різне » Задатчик 4-20ma » 2026-05-15 20:26:41
Потрібен Задатчик тока 4-20ma на ардуіно
Хтось таке робив?
Робив, тільки без ардуіно. LM317 - 1 шт, резистор на 62 Ом - 1 шт, потенціометр 270 Ом - 1 шт.
Чи вам треба з електронним керуванням? Який діапазон вихідної напруги?
#18 Re: Проекти » Термостанція для ребола BGA » 2026-05-07 23:41:26
Не тримає температуру , пригає на 5-10 градусів.
Як саме пригає?
Виведіть та збережіть діагностику: Input, Output та Setpoint для того канала, який налаштовуєте. Покажіть її тут. Бажано побудувати графік - по ньому буде видно, що там відбувається.
Якщо утворюються автоколивання, то або перерегуляція - завеликі коефіцієнти P або I, або недостатнє демпферування - замалий коефіцієнт D. Ще може бути завеликий період циклу, але у вас 250 мс - для нагрівача має бути ок.
Я так поняв проблема в PID коефіціентах.Вже 6 годин махаюсь і поки ніяк
У вас, наскільки бачу, коефіцієнти прямо в скетчі захардкоджені? І кожний раз перезбираєте і прошиваєте? Звісно, так підбирати - велика морока.
Перепишіть скетч, щоб задавати коефіцієнти з компа. Тоді підбирайте класичними методами.
Оффтопік порада.
if(Time>TimePidWork+250){- ніколи не порівнюйте беззнакові таймпоінти без врахування переповнення типів. Або порівнюйте беззнакові тривалості, або зберігайте таймпоінти як числа зі знаком. Але коректне перетворення беззнакових типів у знакові в C++ не зовсім тривіальне, так що краще просто порівнюйте тривалість від початкового таймпоінта до поточного із константою.
Звісно, в цьому конкретному випадку це не критичний баг, але корисно мати звичку писати код без помилок.
#19 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-28 21:54:41
А так?
Так уже краще. ChatGPT вчиться? ![]()
додати кондюк 0.1 мкФ на землю (A → GND)
З підтяжкою 10 кОм такий конденсатор утворюватиме ФНЧ з частотою зрізу 160 Гц. А з вбудованою - десь 60-70 Гц. На 300 об/хв може ще не впливатиме, але якщо більше - вже не годиться.
Щоб позбутись "брудних" фронтів (якщо вони там дійсно є і заважають), можна просто рахувати по обом фронтам фази A скільки раз фаза B змінила значення на протилежне від попереднього.
либа от Paul Stoffregen
нюанс-либа рахує x4-10 P/R → 40 імпульсів/оберт
То вже якесь збочення.
#20 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-28 20:07:03
Тобто варто взяти 32 розрядний проц - і можна за атомарність не паритись?
Якщо атомарність доступа до слова цієї розрядності гарантується апаратно, то для одиничного запису чи читання - так, можна не паритись. Лише впевнитись, що змінна розміщується з необхідним вирівнюванням (зазвичай це також гарантується). Але на деяких архітектурах може довестись паритись із реордерінгом інструкцій та memory барʼєрами, а іноді і з інвалідацією кеша ![]()
А при read/modify/write все одно потрібна синхронізація.
#21 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-28 19:19:30
В цьому скетчі вже баги.
1. 16-бітна змінна pulses змінюється в ISR, а читається неатомарно.
2.
if (pulses != last) {
...
Serial.println(pulses);
last = pulses;Тут race condition. При всіх трьох зчитуваннях pulses може мати три різні значення.
#22 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-28 14:32:21
Можливо, проблема саме в цьому енкодері?
Можливо. Але дуже малоймовірно. Також можливо, що проблема десь у зʼєднаннях, платі чи контролері. Це теж малоймовірно.
Майже впевнений, що проблема в коді, а коду ми не бачили.
Напишіть програму, що пише стан входів у Serial. Повільно обертайте енкодер і перевірте, чи бачите очікуваний квадратурний сигнал.
Якщо все ок, напишіть мінімальну програму, яка обчислює швидкість обертів і видає результат в Serial. Якщо працює не так як очікується, то показуйте код.
Мені потрібне точне регулювання обертів
Точне - це яке в цифрах?
При інтервалі в 1 секунду з PPR 10 точність виміру не перевищуватиме 5-6 об/хв. При 30 об/хв це 20%.
А точність регулювання, навіть при ідеально підібраних коефіцієнтах PID, залежатиме як від точності виміру, так і від властивостей керованої системи: потужності двигуна, характеристики навантаження.
Ви можете лише визначити, що відхилення поточної швидкості від цільової перевищує заданий поріг.
#23 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-27 23:11:47
а 2000 обертів у автора atmega не потягнула.
Не дивно, з енкодером на 2000 PPR. Якщо іншого нема, а треба оберти в секунду при обертанні в один бік на такій швидкості, то можна тільки фазу Z читати. Тоді 1 PPR виходить, можна рахувати хоч мільйон об/хв.
А ще у атмеги є input capture, якщо програмної швидкодії недостатньо.
#24 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-27 20:53:23
https://forum.arduino.ua/img/members/3885/Omron-E6B2_CWZ6C.zip
В цій імплементації зміна стану відбувається лише по одному фронту однієї фази. Такий метод в більшості випадків нормально працює при постійному обертанні вала. Але на граничних умовах - наприклад, покачування вала в обидва боки - будуть хибні спрацювання.
Повноцінний конечний автомат квадратурного енкодера виглядає десь так: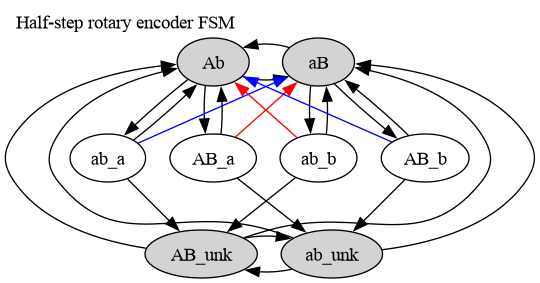
що досить просто реалізується за допомогою таблиці переходів.
#25 Re: Проекти » скетч, що керує електродвигуном із зворотним зв’язком » 2026-04-27 00:14:06
2. Енкодер на валу двигуна підраховує кількість імпульсів за заданий інтервал часу.
Який діапазон швидкостей обертання?
на один механічний оберт вала енкодера Omron E6B2-CWZ6C щоразу видає нове значення.
Енкодер не видає значення, енкодер видає сигнали. Як ви їх обробляєте?